
What Google’s Patents Reveal About the Future of SEO
Content type
Long-form article
Target word count
2,000 – 3,500
Search intent
Informational
Audience
SEO pros & marketers
What Google’s Patents Reveal About the Future of SEO
Google’s patent filings are a goldmine for SEO strategists. Discover what they reveal about ranking signals, content quality, and what to prioritize before algorithm changes hit.
Most SEOs wait for Google to announce what matters. The savvy ones read the patents. While Google rarely explains its algorithm in plain language, its patent filings — publicly available through the US Patent and Trademark Office and Google Patents — tell a detailed story about where search is heading. From entity recognition and passage indexing to authorship signals and site reputation, the clues are hiding in plain sight. This article breaks down the most significant patents filed by Google and what they mean for your SEO strategy today — and tomorrow.
FreeCash
The average user earned $28 yesterday, and most get their first payout in under 17 minutes. Over $50M paid out.
Earn Haus
Over 5,588 surveys available with same-day payouts via PayPal, Venmo, or eCheck.
Swagbucks
Earn rewards for surveys, shopping, and watching videos — earnings up to $210/mo.
HealthyWage
HealthyWage has paid thousands to real winners like Brittney M. ($1,057) and Mariana A. ($10,899) for hitting their fitness targets.
- Why Google patents matter for SEO
- Entity-based search & knowledge graphs
- Authorship, E-E-A-T & site reputation signals
- Passage indexing & content granularity
- User engagement as a ranking signal
- Link quality vs. link quantity
- AI, LLMs & the next generation of search
- Your future-proof SEO action plan
- Why Google patents matter for SEO
Every year, Google makes thousands of changes to its search algorithm. Most go unannounced. A handful get a blog post. Almost none get a detailed explanation. For SEO professionals, this creates a permanent guessing game — chasing ranking drops, reverse-engineering updates, and debating what Google actually values.
But there’s a source most SEOs overlook entirely: Google’s own patent filings.
What is a patent, and why should SEOs care?
A patent is a legal document filed with the United States Patent and Trademark Office (USPTO) — or its international equivalents — that describes a novel invention in precise technical detail. Companies file patents to protect their intellectual property. Google files hundreds every year, covering everything from hardware to machine learning systems to — crucially — the methods it uses to rank web content.
Unlike press releases or conference talks, patents are not marketing. They are legal documents written to define exactly how a system works. That specificity is what makes them valuable to SEOs. When Google patents a method for evaluating the trustworthiness of a website, or scoring the expertise of an author, it is describing a real mechanism — not an aspiration.
Where to find Google’s patents
Google’s patent filings are publicly available and free to access. The two main sources are:
Google Patents (patents.google.com) — Google’s own search interface for patent databases. You can search by keyword, inventor name, or assignee (search “Assignee: Google LLC” to filter Google-owned patents).
USPTO Public Search (ppubs.uspto.gov) — The official US database. More granular filtering but a steeper learning curve.
Many of Google’s most influential SEO-related patents were filed by engineers like Bill Slawski, whose site SEO by the Sea spent years translating patents into plain language — making it one of the most valuable resources in the field.
How to read a patent without an engineering degree
Patents follow a standard structure. You don’t need to read every word — you need to know where to look:
Title & abstract — The one-paragraph summary. This tells you what the invention is and its core purpose. Start here.
Claims — The legally binding section that defines exactly what the patent protects. Claims are numbered and often dense, but Claim 1 is usually the broadest and most useful for SEOs.
Description / detailed description — The long technical section that explains how the system works in practice. This is where the useful insights live. Look for phrases like “ranking signal,” “quality score,” “user feedback,” and “document score.”
Figures — Diagrams of the system. Often easier to interpret than the text and can quickly reveal the structure of a ranking model.
The goal isn’t to understand every line — it’s to extract the intent. What problem is Google trying to solve? What signals is it measuring? What outcomes is it optimizing for?
Patents are signals, not certainties
One important caveat: a filed patent does not guarantee the technology is live in Google Search today. Companies patent ideas speculatively, and some patents never make it into production. Others are filed years before they’re deployed.
What patents do tell you is what Google is thinking about, what problems its engineers are working to solve, and what signals the system is designed to capture. Patterns across multiple patents — especially when they align with observed ranking behavior — are as close to confirmed strategy as the SEO industry gets.
Think of patents the way investors think of earnings calls. No single statement is the whole picture, but the pattern of signals across many filings gives you a reliable map of where the company is heading.
Why this matters more now than ever
As Google integrates large language models and AI-assisted ranking into its core systems, the pace of change is accelerating. Algorithm updates that once came quarterly now arrive continuously. SEOs who rely only on what Google announces publicly are perpetually behind.
Reading patents shifts your posture from reactive to predictive. Instead of recovering from the last update, you’re preparing for the next one.
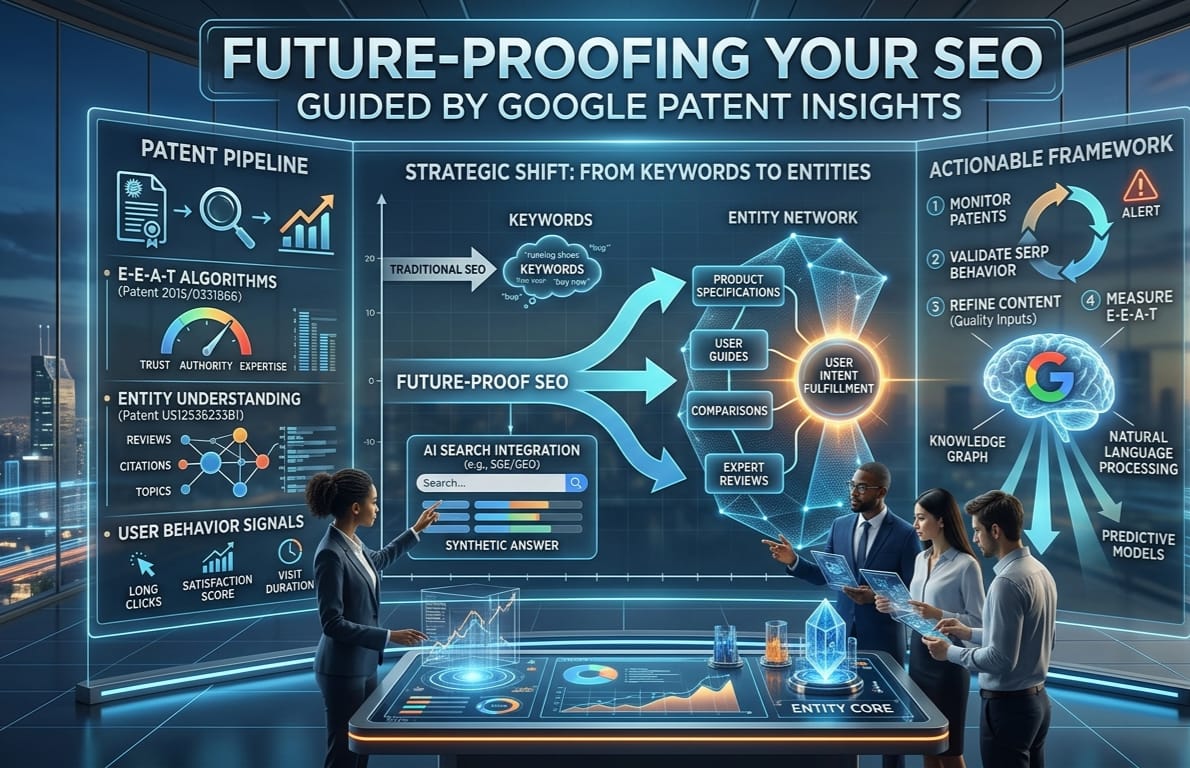
- Entity-based search & knowledge graphs
For most of search’s history, Google operated on a simple premise: match the words in a query to the words on a page. If someone searched “best running shoes,” Google looked for pages that contained those exact words — or close variations of them. Keywords were the currency of SEO, and the game was largely about density, placement, and volume.
That model is now fundamentally outdated.
Google has spent the better part of the last decade rebuilding its understanding of the web around a completely different concept: entities.
What is an entity?
In Google’s framework, an entity is any distinct, identifiable thing — a person, place, organization, concept, product, or event. “Barack Obama” is an entity. “Paris” is an entity. “Diabetes” is an entity. “The 2008 financial crisis” is an entity.
What makes entities powerful is that they exist independently of the words used to describe them. Google understands that “the 44th US president,” “Obama,” and “Barack Hussein Obama II” all refer to the same entity — and it can reason about relationships between entities without relying on keyword matching at all.
This shift was formalized publicly in 2012 when Google introduced the Knowledge Graph — its structured database of entities and the relationships between them. But the patent filings that underpinned that system, and the many that followed, reveal just how deep the rabbit hole goes.
The patents behind entity understanding
Several key Google patents describe how the system identifies, classifies, and connects entities across the web.
One foundational area covers entity extraction — the process by which Google identifies mentions of known entities within a piece of content and maps them to records in its Knowledge Graph. A page about “the history of jazz” that mentions Miles Davis, John Coltrane, and Blue Note Records isn’t just a page about music — in Google’s model, it is a document with verified connections to specific, known entities. Those connections carry weight.
Another set of patents covers entity salience — not just whether an entity is mentioned, but how central it is to the content. A page that mentions “Apple” in passing as part of a broader tech roundup is treated very differently from a page where Apple is the primary subject, discussed in depth across multiple sections. Salience scoring allows Google to understand what a page is truly about, beyond surface-level keyword analysis.
Perhaps most significantly, patents around entity co-occurrence reveal that Google tracks which entities tend to appear together across the web. If authoritative pages about cardiology consistently mention certain treatments, researchers, and institutions together, Google builds a model of that topical neighborhood. Content that fits coherently within that neighborhood is rewarded. Content that appears isolated from it — even if it uses the right keywords — may struggle to rank.
The Knowledge Graph as a trust framework
The Knowledge Graph isn’t just a database of facts. For SEO purposes, it functions as a trust and authority framework.
When your brand, your authors, or your organization has an established presence in the Knowledge Graph — a verified entity with clear attributes and relationships — Google has a stable reference point for evaluating your content. It knows who you are, what you cover, and how you relate to other trusted entities in your space.
When you lack that presence, Google is essentially encountering a stranger. It has to infer your authority from indirect signals alone, which is a slower and less reliable process.
This is one of the reasons why building an entity presence — through structured data, Wikipedia entries, Wikidata profiles, Google Business Profiles, and consistent brand mentions across authoritative sources — has become a foundational SEO task, not an optional add-on.
What this means for content structure
The shift to entity-based search has direct, practical implications for how you should write and structure content.
Write for topics, not just keywords. A page optimized around a single keyword phrase is increasingly thin in Google’s model. A page that thoroughly explores a topic — covering the relevant entities, their relationships, and the questions that surround them — is far more aligned with how Google now evaluates content depth.
Use the language of your topic’s entity neighborhood. If authoritative sources in your niche consistently use certain terms, names, and concepts, your content should too — not for keyword stuffing reasons, but because that vocabulary signals topical coherence. Google is checking whether your content sounds like it belongs in the conversation.
Structure content to make entities explicit. Use clear headings, named sections, and structured data markup (Schema.org) to help Google identify the entities on your page and understand their roles. A page about a medication, for example, benefits enormously from structured data that identifies the drug name, its uses, its manufacturer, and related conditions — all as distinct, labeled entities.
Build depth, not breadth. Thin pages that touch on many topics lightly are becoming harder to rank as entity modeling rewards genuine subject matter depth. A single comprehensive resource that covers one topic thoroughly — with all its relevant entities in proper context — consistently outperforms a collection of shallow pages targeting adjacent keywords.
The bigger picture
The move from keyword search to entity search represents a fundamental change in what Google is trying to do. It is no longer trying to find pages that match a query. It is trying to find sources that genuinely understand a subject.
That distinction changes everything about how content should be planned, written, and structured. The SEOs who recognize this shift and build their content strategy around entity authority — not keyword volume — are the ones building something that compound in value over time, rather than something that gets disrupted by the next algorithm update.

- Authorship, E-E-A-T & site reputation signals
If entity-based search changed how Google understands what a page is about, the evolution of authorship and site reputation signals changed how it evaluates who is behind it — and whether that source deserves to rank.
This is the domain of E-E-A-T: Experience, Expertise, Authoritativeness, and Trustworthiness. Originally a quality framework from Google’s Search Quality Rater Guidelines, E-E-A-T has increasingly been backed by patent filings that describe concrete, measurable signals — not abstract ideals.
From PageRank to people
Google’s original breakthrough was PageRank — the idea that a page’s authority could be measured by the quality and quantity of links pointing to it. It was a brilliant proxy for trust at a time when the web was simpler.
But links can be manipulated. And as the web grew more complex, Google needed additional trust signals that were harder to game. Its patent filings from the last decade reveal a clear direction: moving from page-level authority to author-level and site-level authority modeling.
The shift is significant. Instead of asking only “how many credible sites link to this page?” Google’s systems are increasingly asking “who wrote this, what is their established expertise, and does this site have a consistent reputation for quality in this subject area?”
The authorship patents
Several Google patents describe systems for identifying and evaluating the humans behind content — and using that evaluation as a ranking input.
One important area covers agent rank — a concept first described in a patent filed by Google engineer Amit Singhal. The system describes assigning reputation scores to individual content creators based on the quality and reception of their published work across the web. An author whose articles are consistently cited, linked to, and engaged with by authoritative sources accumulates a higher agent rank — and that score can influence how Google treats new content they publish.
This connects directly to why author bylines, author bio pages, and author Schema markup have become important SEO elements. They give Google the data points it needs to identify an author as a known entity and connect their content to an established reputation profile.
Another set of patents covers implied links and brand mentions — instances where an author or organization is referenced by name without a hyperlink. Google’s systems are designed to recognize these unlinked mentions as trust signals, effectively treating them as soft endorsements. An expert whose name appears frequently in authoritative industry publications — even without direct links back to their site — builds a measurable reputation signal in Google’s model.
Site-level reputation modeling
Beyond individual authors, Google’s patents reveal sophisticated systems for evaluating the reputation of entire domains and sites — not just individual pages.
One particularly significant area involves site quality scoring — systems that assess a site’s overall trustworthiness based on signals like the consistency of its content quality, the expertise of its contributors, how it handles advertising and commercial content, and whether its pages demonstrate genuine depth on the topics they cover.
This has direct implications for a pattern many SEOs have observed: that a strong page on a weak site often underperforms a comparable page on a strong site. Google’s site-level reputation signals act as a multiplier — amplifying the ranking potential of good content on trusted domains, and suppressing it on domains with poor overall quality signals.
Patents also describe systems for detecting topic consistency at the site level. A site that publishes deeply across a defined subject area builds stronger topical authority than one that publishes broadly across unrelated topics. This is why niche authority sites frequently outrank larger generalist publications for specific queries — their site-level entity and topical signals are more concentrated and coherent.
The “Experience” addition and what it signals
When Google added the first “E” — Experience — to its quality framework in 2022, it was signaling something important: that first-hand, lived experience with a topic is now considered a distinct quality dimension, separate from academic or professional expertise.
Patent filings around content evaluation describe signals that attempt to assess whether content reflects genuine personal experience — markers like specific anecdotal detail, first-person narrative structure, and content that goes beyond what could be assembled from secondary sources alone. This is particularly relevant for product reviews, travel content, health and wellness articles, and any category where real-world experience adds meaning that pure research cannot replicate.
The practical implication is clear: content written by someone who has actually used a product, visited a place, or lived with a condition carries signals that AI-generated or heavily aggregated content structurally cannot replicate — at least not yet.
What this means for your SEO strategy
The authorship and reputation signals described across Google’s patents point to a set of practical priorities that should shape how you build content operations.
Invest in real authors with real credentials. Anonymous content or content published under generic bylines misses the authorship signal entirely. Named authors with established web presences, professional profiles, and published work elsewhere give Google the data it needs to score and reward their contributions.
Build author entity profiles. Each author on your site should have a dedicated bio page with structured data markup, links to their work on other authoritative platforms, social profiles, and a clear statement of their expertise. This is the infrastructure that makes author-level trust signals legible to Google’s systems.
Treat your site’s topical focus as a strategic asset. Every time you publish content outside your core subject area without a clear topical bridge, you dilute your site-level entity signals. A focused content strategy — going deep on fewer topics rather than shallow on many — builds the kind of concentrated authority that Google’s reputation models reward.
Earn mentions, not just links. Given the patent evidence around implied links and brand mentions, your off-page strategy should include building genuine visibility in your industry — through contributed articles, expert commentary, podcast appearances, and citations in industry publications. These mentions accumulate as reputation signals even when they carry no link equity.
Audit your site’s overall quality signals. If your domain carries thin content, heavy advertising, inconsistent quality, or a history of low-value pages, those site-level signals suppress even your best content. A quality audit that addresses the weakest pages on your domain is often more impactful than producing new content on a compromised foundation.
Trust as a compounding asset
The deeper insight from Google’s authorship and reputation patents is that trust is not a page-level variable — it is a compounding, site-wide, and author-wide asset that builds over time.
A single well-written article from an unknown author on an unestablished site faces an uphill battle regardless of its quality. The same article, published by a credentialed author on a domain with years of consistent, high-quality content in a defined subject area, enters the index with a significant structural advantage.
This is what future-proofing SEO actually means at the author and site level: building the kind of durable, entity-backed reputation that makes every piece of content you publish more likely to succeed — before a single keyword is researched or a single backlink is built.
Discover more from How to Start Earning Real Money Online
Subscribe to get the latest posts sent to your email.





